Why I Built Claw Recall: AI Agents Need Memory
Every AI conversation is temporary. When context compacts, when you start a new session, when you switch agents — all that context is gone. Decisions made, code reviewed, configurations discussed — lost.
I got tired of re-explaining the same things. So I built Claw Recall.
The problem
I run multiple AI agents. Claude Code for development. Kit for operations. Specialised agents for customer support, analytics, and content. Each agent has its own conversation history that the others can’t see.
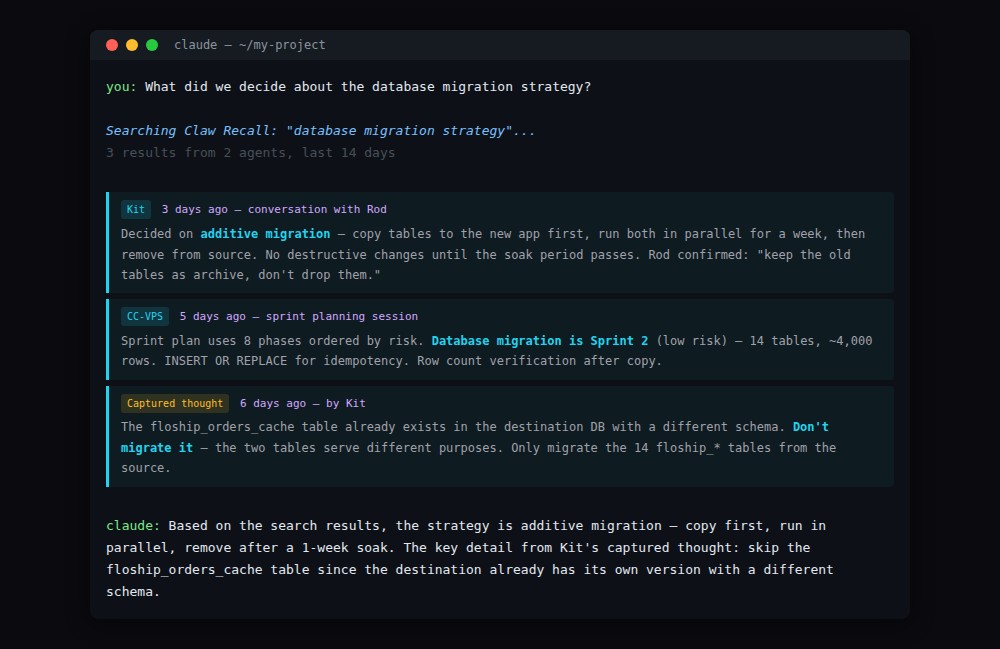
When Claude Code is working on a database migration and I ask Kit about it, Kit has no idea what I’m talking about. When context compaction kicks in mid-conversation, the agent forgets what it was just doing. When I start a new session, I lose all the decisions and discoveries from the last one.
The standard solution — copying and pasting context between agents — doesn’t scale. You can’t paste a week of conversations into a prompt.
What Claw Recall does
Claw Recall indexes every conversation across all agents into a searchable database. Any agent can search what any other agent discussed. It supports:
- Keyword search for specific terms, IDs, or error messages
- Semantic search for conceptual questions (“what did we discuss about the shipping costs?”)
- Captured thoughts — agents can save important information for future recall
- External sources — Gmail, Google Drive, and Slack content, all indexed and searchable
The entire system runs on SQLite with sentence transformer embeddings. Under $1/month to operate.
How agents use it
Every agent has access to Claw Recall via MCP (Model Context Protocol). When an agent needs context it doesn’t have, it searches memory first. This happens dozens of times a day without me asking for it.
For example: I ask Claude Code to investigate a shipping provider billing discrepancy. It searches Claw Recall and finds that Kit discussed this same issue three months ago with a different approach. Now it has that context without me having to remember or explain it.
The architecture
The system is straightforward:
- A watcher monitors session files from every agent and indexes new messages
- A search engine combines FTS5 keyword search with cosine similarity semantic search
- MCP servers (stdio for VPS agents, SSE for remote agents) expose 8 tools
- A capture system lets agents save thoughts and index external sources
Everything lives in a single SQLite database. No external services, no cloud dependencies, no recurring costs beyond the embedding model.
What I learned building it
The hardest part wasn’t the search — it was deciding what to index. Too much noise and search results are useless. Too selective and you miss important context. The solution was layered search: keyword for precision, semantic for recall, with agent and time filters to narrow scope.
The second lesson: agents need to be able to capture thoughts proactively, not just search reactively. When an agent discovers something important — a configuration quirk, a workaround, a decision — it should save that for future agents to find.
Open source
Claw Recall is free and open source. If you’re running multiple AI agents and tired of losing context, check it out on the Claw Recall project page or at github.com/rodbland2021/claw-recall.